The z2m lib to interface with Alexa node-red-contrib-alexa-remote2-applestrudel is going to be stucked due to the amazon decision to hide events.
I invested a lot (too much) to develop a holistic solution in NR in order to manage voice inputs based on that lib, so I need to look for other solutions.
What i need is a simple device able to listen for a voice input (triggered by a wake word) with a nodered flow able to catch it. It should be able to get inputs in italian. Nothing more nothing less.
Are there mature solutions able to perform such a task?
Are available stable NR libs to use google devices inputs?
Are there other contribs able to trap voice inputs events (I cannot immage such a cse, but who knows?)
No problem. Moral support is enough.
I wrote a python trivial general service (to be hosted by the raspi server) where it is assumed a producer (microphone) send a json data structure (I don’t know what hell the microphone output is …) to the service. the service call a manager (wake word analysis) and then send the result (if a wake word is found) with the speak-to.text content.
I need now to understand at least :
what (data type) the microphone produce and how (rest, socket ?) it sends the stuff to the service
how the service can call the wake processor passing the received data
who, how, when and where the voice stream is reduced to a text
Some collected news.
The Atom Echo is not feasible for wake word detection. Such a function requires much more power than an ESP32 cpu can provide. So You should be prepared to move this module to an external CPU with openwakeword or porcupine framework. Other stages is the speak to text . Again there are solution requiring quite a bit of.
I think this project is much over the effort I can/want to dedicate to.
FYI there is a new update to applestrudel that seems to have fixed the issue for now. But I agree, I feel like we are on borrowed time at this point. I am currently playing around with a ESP32-S3-BOX and willow, but nothing to report right now.
It has a docker image that I got working on Unraid without any fuss, so presumably yes, it could be integrated into the “User Integrations” of CC. Only issue is that Willow is still pretty new, so afaik, there is no way to integrate stuff like the GPIO or sensor boards included with the boxes.
We are currently considering the best way to go about user control of these GPIOs. Ideally we could use esphome or some other established/standard way to configure them but we haven’t completely thought this through yet. - Hardware - Willow
The ESP BOX provides 16 GPIOs to the user that are readily accessed from sockets on the rear of the device. We plan to make these configurable by the user to enable all kinds of interesting maker/DIY functions. - What Willow Is (And Isn’t) - Willow
Did you test the voice recognition? The only supported lsanguage are currently chinese and english. To replace echos in my family It should recognize italian too.
May I get the recognized command outside the box ? How ?
Sorry for so many questions…
That is probably a dealbreaker then, at least for now.
By default this is its intended purpose, its default programming is simply a speech to text engine.
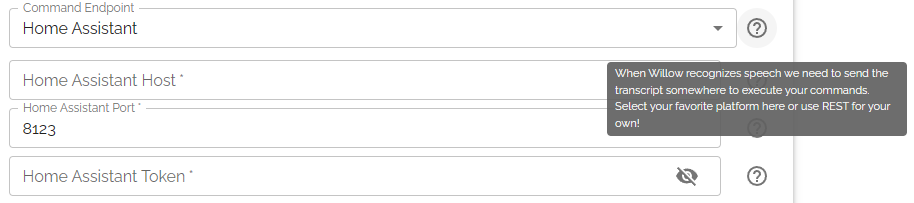
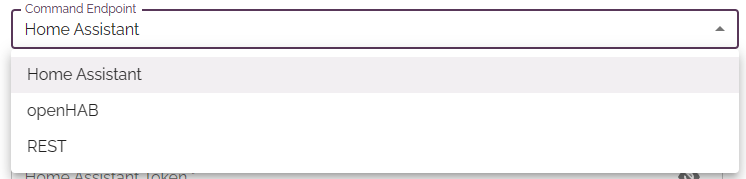
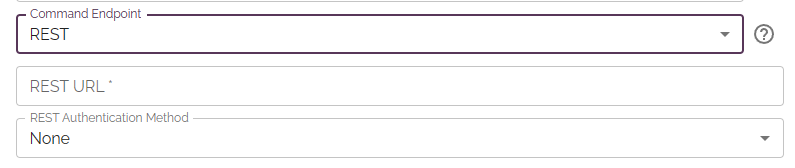
You can send that text to a variety of sources like Home Assistant, OpenHAB, or just raw to some listener using their REST API:
I haven’t played too much around with it, but it seems to be very quick and decently accurate. It might struggle with heavy accents though. It is going to be a while until you get something that is as adaptable as Alexa or GH.
Ok At this point Home Assistants progress in the Year of voice is progressing pretty well, and seems to have some real potential, even better it only costs about $13 to build the voice assistant hardware,
I am still catching up on the details, but it seems like they have made a ton of progress, including the ability to create and train your own CUSTOM wake words!!!
I have NOT made one or tested it out yet myself, its on my todo list (meaning it’ll likely be months before i even order one), so whoever beats me to testing it out please report back!
Ive been watching this. The process still seems complex for the average joe. Not anything i dont think i could muddle through, but seems like several moving parts have to come into alignment for it to work. Im looking forward to it becoming slightly more user friendly.
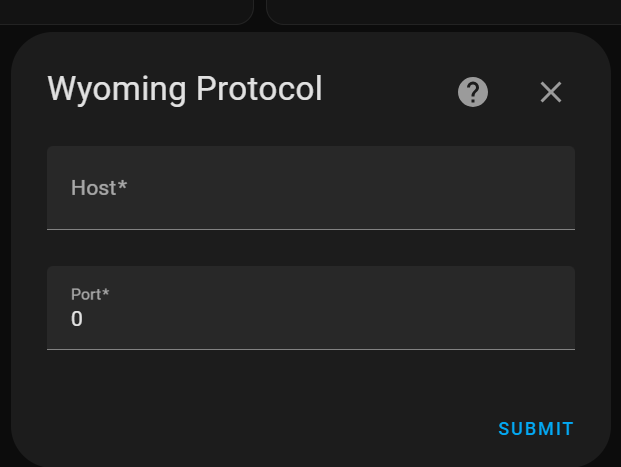
I am trying the $13 voice assistant, but as soon as I tried to setup the wyoming protocol and saw this, I bailed:
This will take someone more intimate with HA and core than I, or some instructions at roadblocks.
whenever it has made it to the top of my to buy and then to do list I’ll see about doing a walkthrough covering any sticky points or things the official docs missed
I’ll presumably go with esp32 se and Willow for a try. I do not really want to add any other piece of cake to my system. Frankly I even expected to reduce them with OLL, but It was long long time ago.